数据结构排序总结
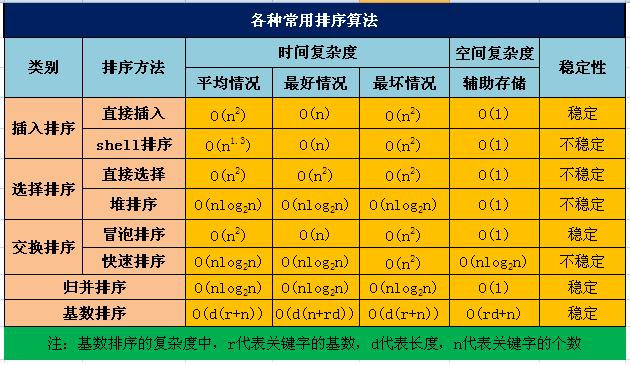
总过四大类排序:插入、选择、交换、归并(基数排序暂且不算)
比较高级一点的(时间复杂度低一点得)shell排序,堆排序,快速排序(除了归并排序)都是不稳定的,在加上低一级的选择排序是不稳定的。
比较低级一点的(时间复杂度高一点的)插入排序,冒泡排序,归并排序,基数排序都是稳定的。
(4种不稳定,4种稳定)。
怎么记忆初始序列是否对元素的比较次数有关:
|
|
对于直接插入排序:
当最好的情况,如果原来本身就是有序的,比较次数为n-1次(分析(while (j >= 0 && temp < R[j]))这条语句),时间复杂度为O(n)。
当最坏的情况,原来为逆序,比较次数为2+3+…+n=(n+2)(n-1)/2次,而记录的移动次数为i+1(i=1,2…n)=(n+4)(n-1)/2次。
如果序列是随机的,根据概率相同的原则,平均比较和移动的次数为n^2/4.
|
|
选择排序不关心表的初始次序,它的最坏情况的排序时间与其最佳情况没多少区别,其比较次数都为 n(n-1)/2,交换次数最好的时候为0,最差的时候为n-1,尽管和冒泡排序同为O(n),但简单选择排序性能上要优于冒泡排序。但选择排序可以 非常有效的移动元素。因此对次序近乎正确的表,选择排序可能比插入排序慢很多。
冒泡排序:
最好的情况,n-1次比较,移动次数为0,时间复杂度为O(n)。
最坏的情况,n(n-1)/2次比较,等数量级的移动,时间复杂度为O(O^2)。
|
|
希尔排序初始序列对元素的比较次数有关。
|
|
|
|
|
|
各排序算法整体分析
冒泡排序、插入排序、希尔排序以及快速排序对数据的有序性比较敏感,尤其是冒泡排序和插入排序;
选择排序不关心表的初始次序,它的最坏情况的排序时间与其最佳情况没多少区别,其比较次数为 n(n-1)/2,但选择排序可以 非常有效的移动元素。因此对次序近乎正确的表,选择排序可能比插入排序慢很多。
冒泡排序在最优情况下只需要经过n-1次比较即可得出结果(即对于完全正序的表),最坏情况下也要进行n(n-1)/2 次比较,与选择排序的比较次数相同,但数据交换的次数要多余选择排序,因为选择排序的数据交换次数顶多为 n-1,而冒泡排序最坏情况下的数据交换n(n-1)/2 。冒泡排序不一定要进行 趟,但由于它的记录移动次数较多,所以它的平均时间性能比插入排序要差一些。
插入排序在最好的情况下有最少的比较次数 ,但是它在元素移动方面效率非常低下,因为它只与毗邻的元素进行比较,效率比较低。
希尔排序实际上是预处理阶段优化后的插入排序,一般而言,在 比较大时,希尔排序要明显优于插入排序。
快速排序采用的“大事化小,小事化了”的思想,用递归的方法,将原问题分解成若干规模较小但与原问题相似的子问题进行求解。快速算法的平均时间复杂度为O(nlogn) ,平均而言,快速排序是基于关键字比较的内部排序算法中速度最快者;但是由于快速排序采用的是递归的方法,因此当序列的长度比较大时,对系统栈占用会比较多。快速算法尤其适用于随机序列的排序。
因此,平均而言,对于一般的随机序列顺序表而言,上述几种排序算法性能从低到高的顺序大致为:冒泡排序、插入排序、选择排序、希尔排序、快速排序。但这个优劣顺序不是绝对的,在不同的情况下,甚至可能出现完全的性能逆转。
对于序列初始状态基本有正序,可选择对有序性较敏感的如插入排序、冒泡排序、选择排序等方法
对于序列长度 比较大的随机序列,应选择平均时间复杂度较小的快速排序方法。
各种排序算法都有各自的优缺点,适应于不同的应用环境,因此在选择一种排序算法解决实际问题之前,应当先分析实际问题的类型,再结合各算法的特点,选择一种合适的算法
这里特别介绍下快速排序:
快速排序的时间主要耗费在划分操作上,对长度为k的区间进行划分,需要k-1次关键字比较。
(1)最坏的时间复杂度
最坏情况是每次划分选取的基准都是当前无序区中关键字最小(或最大)的记录,划分的结果是基准左边的子区间为空(或右边的子区间为空),而划分所得的另一个非空的子区间中记录数目,仅仅比划分前的的无序区中记录个数减少一个。
因此,快速排序必须做n-1次划分,第i次划分开始区间长度为n-i+1,所需的比较次数为n-i(1<=i<=n-1),故总的比较次数达到最大值:n(n-1)/2;
如果按上面给出的划分算法,每次取当前无序区的第1个记录为基准,那么当文件的记录已按递增序(或递减序)排列时,每次划分所取的基准就是当前无序区中关键字最小(或最大)的记录,则快速排序所需的比较次数反而最多。
(2)最坏的时间复杂度
在最好情况下,每次划分所取的基准都是当前无序区的”中值”记录,划分的结果是基准的左、右两个无序子区间的长度大致相等。总的关键字比较次数:
0(nlgn)
(3)平均时间复杂度
尽管快速排序的最坏时间为O(n2),但就平均性能而言,它是基于关键字比较的内部排序算法中速度最快者,快速排序亦因此而得名。它的平均时间复杂度为O(nlgn)。
(4)空间复杂度
快速排序在系统内部需要一个栈来实现递归。若每次划分较为均匀,则其递归树的高度为O(lgn),故递归后需栈空间为O(lgn)。最坏情况下,递归树的高度为O(n),所需的栈空间为O(n)。